07. Supervised Fine-Tuning#
⚡Compute Note: I recommend running this notebook on a node with 1x H200 GPU.
This notebook fine-tunes the pretrained ShrayGPT model from notebook 06 into an instruction-following assistant using supervised fine-tuning (SFT). We will:
Extend the
r50k_basetokenizer with conversation-specific special tokens.Build an instruction dataset by blending Alpaca, Dolly v2, and UltraChat samples.
Pack the conversations into fixed-length training chunks that match the model’s block size.
Fine-tune the base checkpoint with PyTorch Lightning and sample the resulting instruct model.
SFT allows us to tune the model on Q&A style datasets, and make the responses more useful to a chatbot-like conversation.
import random
from typing import Dict, Iterable, List, Optional, Sequence, Tuple
import lightning as L
import torch
import torch.nn as nn
from datasets import interleave_datasets, load_dataset
from torch.utils.data import DataLoader, Dataset
import tiktoken
from src.shraygpt import ShrayGPT
tokenizer = tiktoken.get_encoding("r50k_base")
model = ShrayGPT.load_from_checkpoint("checkpoints/shraygpt-base.ckpt", map_location="cpu")
model.hparams.learning_rate_adamw = 1e-4
model.hparams.learning_rate_muon = 5e-4
model.hparams.aux_loss_weight = 5e-4
We shall use the Alpaca and Dolly SFT datasets from Huggingface.
# Load a sample of the Alpaca dataset
alpaca = load_dataset("yahma/alpaca-cleaned", split='train')
print("--- Alpaca Dataset Examples ---")
for i, example in enumerate(iter(alpaca.take(3))):
print(f"\n--- Example {i+1} ---")
print(example['instruction'][:500])
print(example['output'][:500])
# Load a sample of the Dolly datase
dolly = load_dataset("databricks/databricks-dolly-15k", split='train')
print("\n--- Dolly Dataset Examples ---")
for i, example in enumerate(iter(dolly.take(3))):
print(f"\n--- Example {i+1} ---")
print(example['instruction'][:500])
print(example['response'][:500])
--- Alpaca Dataset Examples ---
--- Example 1 ---
Give three tips for staying healthy.
1. Eat a balanced and nutritious diet: Make sure your meals are inclusive of a variety of fruits and vegetables, lean protein, whole grains, and healthy fats. This helps to provide your body with the essential nutrients to function at its best and can help prevent chronic diseases.
2. Engage in regular physical activity: Exercise is crucial for maintaining strong bones, muscles, and cardiovascular health. Aim for at least 150 minutes of moderate aerobic exercise or 75 minutes of vigorous exerci
--- Example 2 ---
What are the three primary colors?
The three primary colors are red, blue, and yellow. These colors are called primary because they cannot be created by mixing other colors and all other colors can be made by combining them in various proportions. In the additive color system, used for light, the primary colors are red, green, and blue (RGB).
--- Example 3 ---
Describe the structure of an atom.
An atom is the basic building block of all matter and is made up of three types of particles: protons, neutrons, and electrons. The structure of an atom can be described as a nucleus at the center surrounded by a cloud of electrons.
The nucleus of an atom is made up of protons and neutrons. Protons are positively charged particles and neutrons are neutral particles with no charge. Both of these particles are located in the nucleus of the atom, which is at the center of the atom and contains mos
--- Dolly Dataset Examples ---
--- Example 1 ---
When did Virgin Australia start operating?
Virgin Australia commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route.
--- Example 2 ---
Which is a species of fish? Tope or Rope
Tope
--- Example 3 ---
Why can camels survive for long without water?
Camels use the fat in their humps to keep them filled with energy and hydration for long periods of time.
Now let’s format the conversations and fine-tune the model.
ROLE_PREFIXES = {
"system": 'System:',
"user": "User:",
"assistant": "Assistant:",
}
DEFAULT_SYSTEM_PROMPT = "You are ShrayGPT, a helpful and concise AI assistant."
def format_conversation(messages: Sequence[Tuple[str, str]], default_system: str = DEFAULT_SYSTEM_PROMPT) -> Optional[str]:
'''Convert a list of (role, content) pairs into a single conversation string.'''
formatted: List[str] = []
has_system = any(role == "system" for role, _ in messages)
if not has_system:
formatted.append(f"{ROLE_PREFIXES['system']} {default_system.strip()}")
for role, content in messages:
prefix = ROLE_PREFIXES.get(role)
text = content.strip()
if prefix is None:
continue
formatted.append(f"{prefix} {text}")
if not formatted:
return None
return "\n\n".join(formatted)
def preprocess_dataset(example: Dict[str, str]) -> Dict[str, Optional[str]]:
instruction = example["instruction"].strip()
input_text = example.get("input", "").strip()
response = example["output"].strip() if "output" in example else example["response"].strip()
if input_text:
user_prompt = f"{instruction}\n\n{input_text}"
else:
user_prompt = instruction
conversation = [
("system", DEFAULT_SYSTEM_PROMPT),
("user", user_prompt),
("assistant", response),
]
return {"text": format_conversation(conversation)}
alpaca_sft = alpaca.map(preprocess_dataset, remove_columns=alpaca.column_names)
dolly_sft = dolly.map(preprocess_dataset, remove_columns=dolly.column_names)
# Filter out any examples where text is None
alpaca_sft = alpaca_sft.filter(lambda x: x["text"] is not None)
dolly_sft = dolly_sft.filter(lambda x: x["text"] is not None)
combined_sft = interleave_datasets([alpaca_sft, dolly_sft], probabilities=[0.5, 0.5], seed=42, stopping_strategy="all_exhausted")
train_test_sft = combined_sft.train_test_split(test_size=0.01, seed=42)
from torch.utils.data import IterableDataset, DataLoader
import torch.distributed as dist
torch.set_num_threads(1)
BLOCK_SIZE = 1024 # SFT can use a shorter context than the 06 pretraining run.
PAD_ID = 0 # or whichever id you want as pad
LABEL_PAD_ID = -100 # CrossEntropy ignore_index
class IterableTextDataset(IterableDataset):
def __init__(self, tokenizer, hf_dataset, block_size):
self.tokenizer = tokenizer
self.hf_dataset = hf_dataset
self.block_size = block_size
def _rank_world(self):
if dist.is_available() and dist.is_initialized():
return dist.get_rank(), dist.get_world_size()
return 0, 1
def __iter__(self):
rank, world = self._rank_world()
ds = self.hf_dataset
if hasattr(ds, "shard"):
try:
ds = ds.shard(num_shards=world, index=rank, contiguous=True)
except IndexError:
return
buffer = []
for item in ds:
if 'text' in item and item['text'] is not None:
toks = self.tokenizer.encode(item['text'])
# add an end marker if you like; otherwise omit the following line
# toks += [self.tokenizer.eot_token]
buffer.extend(toks)
# full blocks (no padding needed)
while len(buffer) >= self.block_size + 1:
x = torch.tensor(buffer[:self.block_size], dtype=torch.long)
y = torch.tensor(buffer[1:self.block_size+1], dtype=torch.long)
yield x, y
buffer = buffer[self.block_size:]
# tail: right-pad and ignore in loss
if len(buffer) > 1:
seq_len = min(self.block_size, len(buffer) - 1) # number of *real* positions
x = torch.full((self.block_size,), PAD_ID, dtype=torch.long)
y = torch.full((self.block_size,), LABEL_PAD_ID, dtype=torch.long) # ignore by default
# fill the real part
real_x = torch.tensor(buffer[:seq_len], dtype=torch.long)
real_y = torch.tensor(buffer[1:seq_len+1], dtype=torch.long)
x[:seq_len] = real_x
y[:seq_len] = real_y
yield x, y
train_dataset_full = IterableTextDataset(tokenizer, train_test_sft.get("train"), BLOCK_SIZE)
val_dataset_full = IterableTextDataset(tokenizer, train_test_sft.get("test"), BLOCK_SIZE)
train_loader = DataLoader(
train_dataset_full,
batch_size=14,
num_workers=2,
prefetch_factor=2,
drop_last=True,
pin_memory=True # Helps speed up data transfer to the GPU
)
val_loader = DataLoader(
val_dataset_full,
batch_size=14,
num_workers=2,
prefetch_factor=2,
drop_last=True,
pin_memory=True # Helps speed up data transfer to the GPU
)
Now let’s tune the model!
import lightning as L
from lightning.pytorch.callbacks import ModelCheckpoint, LearningRateMonitor
torch._dynamo.config.capture_scalar_outputs = True
torch.set_float32_matmul_precision('medium')
from huggingface_hub import login
from dotenv import load_dotenv
load_dotenv()
login(token=os.getenv("HF_API_TOKEN"))
class GenerateTextCallback(L.Callback):
"""A PyTorch Lightning callback to generate text samples at the end of each validation epoch."""
def __init__(self, prompts, tokenizer, every_n_steps=100):
super().__init__()
self.prompts = prompts
self.tokenizer = tokenizer
self.every_n_steps = every_n_steps
def on_validation_epoch_end(self, trainer, pl_module):
if trainer.global_step == 0 or trainer.global_step % self.every_n_steps != 0:
return
if not trainer.is_global_zero:
return # only rank 0 prints/logs text
pl_module.print(f"\n\n--- Generating text at step {trainer.global_step} ---")
tb = getattr(trainer.logger, "experiment", None)
for i, prompt in enumerate(self.prompts):
formatted_prompt = format_conversation([
("system", DEFAULT_SYSTEM_PROMPT),
("user", prompt),
("assistant", ""),
])
start_tokens = self.tokenizer.encode(formatted_prompt)
context = torch.tensor(start_tokens, dtype=torch.long, device=pl_module.device).unsqueeze(0)
generated_tokens = pl_module.generate_nocache(context, max_new_tokens=100, temperature=0.7, top_k=20)
generated_text = self.tokenizer.decode(generated_tokens[0].tolist())
pl_module.print(f"PROMPT: '{prompt}'")
pl_module.print(f"GENERATED: {generated_text}\n")
if tb is not None and hasattr(tb, "add_text"):
tb.add_text(f"samples/prompt_{i}", f"**Prompt:** {prompt}\n\n**Generated:** {generated_text}",
global_step=trainer.global_step)
callback = GenerateTextCallback(prompts=["What are the primary colors?", "What is 1 + 1?", "What is the color of the sky?"],
tokenizer=tokenizer, every_n_steps=1000)
checkpoint_cb = ModelCheckpoint(
dirpath="checkpoints/",
filename="shraygpt-{epoch:02d}-{step:05d}-{val_loss:.3f}",
monitor="val_loss",
mode="min",
save_top_k=3,
save_last=True,
)
lr_monitor = LearningRateMonitor(logging_interval="step")
trainer = L.Trainer(max_steps=200_000, accelerator='auto', devices=1, precision='bf16-mixed', strategy='auto',
num_sanity_val_steps=0, limit_train_batches=1000, limit_val_batches=100,
callbacks=[callback, checkpoint_cb, lr_monitor],
logger=L.pytorch.loggers.TensorBoardLogger("logs/"), log_every_n_steps=1)
model.automatic_optimization = False
trainer.fit(model, train_loader, val_loader)
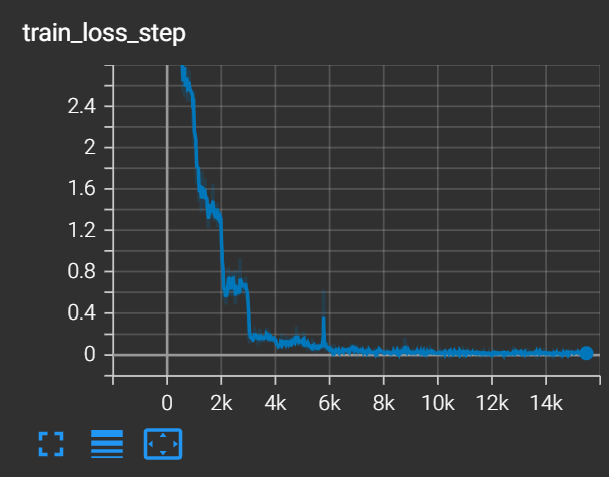
The training curve is shown here.
Now let’s see how the model performs.
model = ShrayGPT.load_from_checkpoint("checkpoints/shraygpt-instruct.ckpt")
prompt = "Describe ways to reduce air pollution."
formatted_prompt = format_conversation([
("system", DEFAULT_SYSTEM_PROMPT),
("user", prompt),
("assistant", ""),
])
start_tokens = tokenizer.encode(formatted_prompt)
context = torch.tensor(start_tokens, dtype=torch.long, device=model.device).unsqueeze(0)
generated_tokens = model.generate_nocache(context, max_new_tokens=100, temperature=0.7, top_k=20)
generated_text = tokenizer.decode(generated_tokens[0].tolist())
print(generated_text)
System: You are ShrayGPT, a helpful and concise AI assistant.
User: Describe ways to reduce air pollution.
Assistant:
1. Encouraging the use of public transportation: By reducing the number of vehicles on the road, you can significantly reduce the number of vehicles on the road, which in turn reduces pollution caused by harmful emissions.
2. Being more responsible: Consider the impact of measures that need to be taken to reduce air pollution, such as green spaces, fresh air, and renewable sources of energy such as wind, solar, and hydro power.
3. Use public transportation: In addition
Pretty neat!