03. Advancing our LLM#
⚡Compute Note: I recommend running this notebook on a node with 1x H200 GPU.
Now that we have seen the entire process (mostly, anyways) of pre-training an LLM, let’s understand what it takes for us to build something like the most advanced language models of today. I highly recommend watching the Stanford CS336 lecture on Architectures.
import lightning as L
from torch.utils.data import Dataset, DataLoader
import tiktoken
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
First thing we shall change/augment in our tiny LLM example from before is the normalization. Instead of post-norm, we now do a pre-norm. The idea is to have as clean residual chain as possible. Post-norm is far less stable as Pre-norm.

Another departure from the GPT work is the use of RMSNorm instead of LayerNorm. It is faster (fewer params and calculations) and just as good.

class RMSNorm(nn.Module):
"""Root Mean Square Layer Normalization."""
def __init__(self, d_model, eps=1e-5):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(d_model))
def forward(self, x):
# The formula is: x * (1 / sqrt(mean(x^2) + eps)) * weight
norm_x = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
return norm_x * self.weight
Everyone today uses pre-norm
Intuition: Keep good parts of the residual connections
Observations: Nice gradient flows and fewer spikes
Most people do RMSNorm
Works as well as LayerNorm in practice
Fewer params to move around saving wall-clock time.
Why RMSNorm + pre-norm?
Pre-norm keeps gradients flowing through residual paths, which matters a lot as depth grows.
RMSNorm rescales activations based on their root-mean-square, giving us LayerNorm-like stabilisation without the extra bias term.
In practice we drop it in place of LayerNorm whenever we see faster convergence or want to shave off a bit of compute.
Another interesting change would be in the activation function. ReLU is a great and simple activation function to choose, but the Gated Linear Units (GLUs) have taken the world by a storm since the works from Google in 2023. GLUs modify he first part of the FFN. Instead of a linear + ReLU unit, we multiply with an entry-wise linear term. Hence, we get, \(max(0, Wx) \cdot xV\). Note that we have an additional parameter V here, because of which the hidden dimension is usually scaled by 2/3 to maintain the same number of params. This gives a gated and recurrent variant of the ReLU + FFN. We can then further enhance it by using the Swish function that makes it more differentiable.
SwiGLU FeedForward:
Two linear projections (
w1andw2) produce parallel streams: one gates the other after a smoothSiLUactivation.The gated product is then projected back to the model dimension, giving richer expressivity than a vanilla GELU MLP for roughly the same FLOPs.
Adjust
multif you want to keep parameter counts comparable when experimenting with different hidden sizes.
class SwiGLU(nn.Module):
def __init__(self, dim, mult=2.68, dropout=0.0):
super().__init__()
inner = int(mult * dim)
self.w1 = nn.Linear(dim, inner, bias=False)
self.w2 = nn.Linear(dim, inner, bias=False)
self.w3 = nn.Linear(inner, dim, bias=False)
self.act = nn.SiLU()
self.dropout = nn.Dropout(0.0)
def forward(self, x):
a = self.w1(x)
b = self.act(self.w2(x))
return self.dropout(self.w3(a * b))
The next thing we shall discuss is the position embedding. Modern architectures such as LLaMA use the Rotary Positional Embeddings (RoPE). The fundamental idea is that we want the positional embeddings to be invariant to the absolute positions. One way to do this is using rotations as inner products are invariant to absolute rotations.
RoPECacheprecomputes the sine and cosine values needed to rotate queries/keys; doing it once avoids recomputation each step.Because rotations are position-dependent but share parameters across heads, we only need to store up to
max_posfor the largest context we expect.If you bump
max_pos, remember this cache sits on the same device as the model so account for the extra memory
import torch
import math
class RoPECache:
"""Precompute cos/sin for positions up to max_pos for even head_dim."""
def __init__(self, head_dim: int, max_pos: int, base: float = 10000.0, device: torch.device | None = None):
assert head_dim % 2 == 0, "RoPE head_dim must be even"
self.head_dim = head_dim
self.base = base
self.device = device
self._build(max_pos)
def get(self, positions: torch.Tensor):
# positions: (T,) or (1,T)
if positions.dim() == 2:
positions = positions[0]
need = int(positions.max().item()) + 1 if positions.numel() > 0 else 1
if need > self.max_pos:
# grow tables
self._build(max(need, int(self.max_pos * 2)))
cos = self.cos[positions] # (T, D/2)
sin = self.sin[positions]
return cos, sin
def _build(self, max_pos: int):
"""(Re)build cos/sin tables for a new max_pos."""
self.max_pos = max_pos
inv_freq = 1.0 / (10000.0 ** (torch.arange(0, self.head_dim, 2, device=self.device).float() / self.head_dim))
t = torch.arange(max_pos, device=self.device).float()
freqs = torch.outer(t, inv_freq) # (max_pos, head_dim/2)
self.cos = torch.cos(freqs)
self.sin = torch.sin(freqs)
def apply_rope_single(x: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor) -> torch.Tensor:
"""Rotate pairs along last dim for RoPE.
x: (B,H,T,D) with D even; cos/sin: (T,D/2)
"""
assert x.size(-1) % 2 == 0
cos = cos.unsqueeze(0).unsqueeze(0) # (1,1,T,D/2)
sin = sin.unsqueeze(0).unsqueeze(0)
x1 = x[..., ::2]
x2 = x[..., 1::2]
xr1 = x1 * cos - x2 * sin
xr2 = x1 * sin + x2 * cos
out = torch.empty_like(x)
out[..., ::2] = xr1
out[..., 1::2] = xr2
return out
Further, and this was not covered in the last piece, we use d_ffn as 4 * d_model. Almost everyone using ReLU style activations will pick the 4 as a factor, and the GLU variants scale the factors by 2/3 so in such cases we keep d_ffn as 8/3 * d_model. There is also empirical evidence to support this from the Scaling Laws, Kaplan 2020 paper.
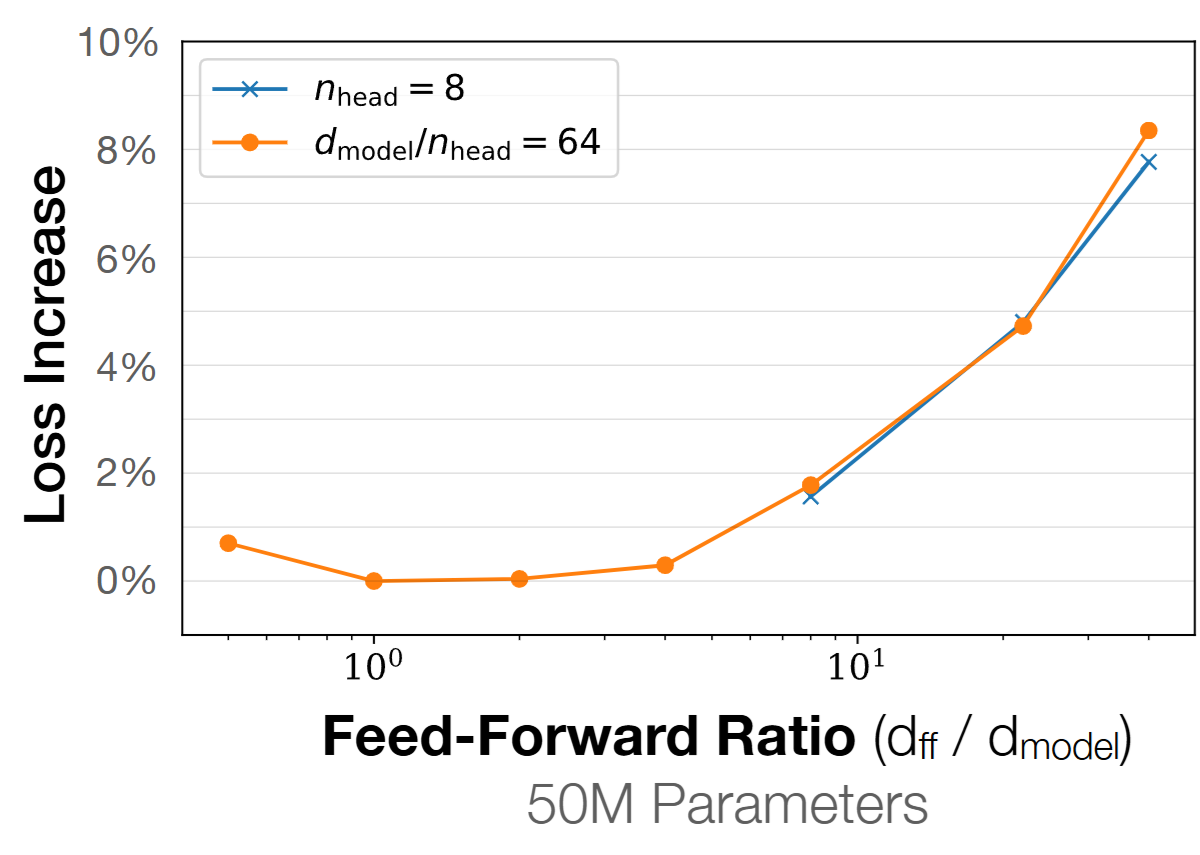
There also is a sweet spot for d_model / n_layer which is around 128 for large models. Another plot from the Scaling Laws, Kaplan 2020 paper shows this.
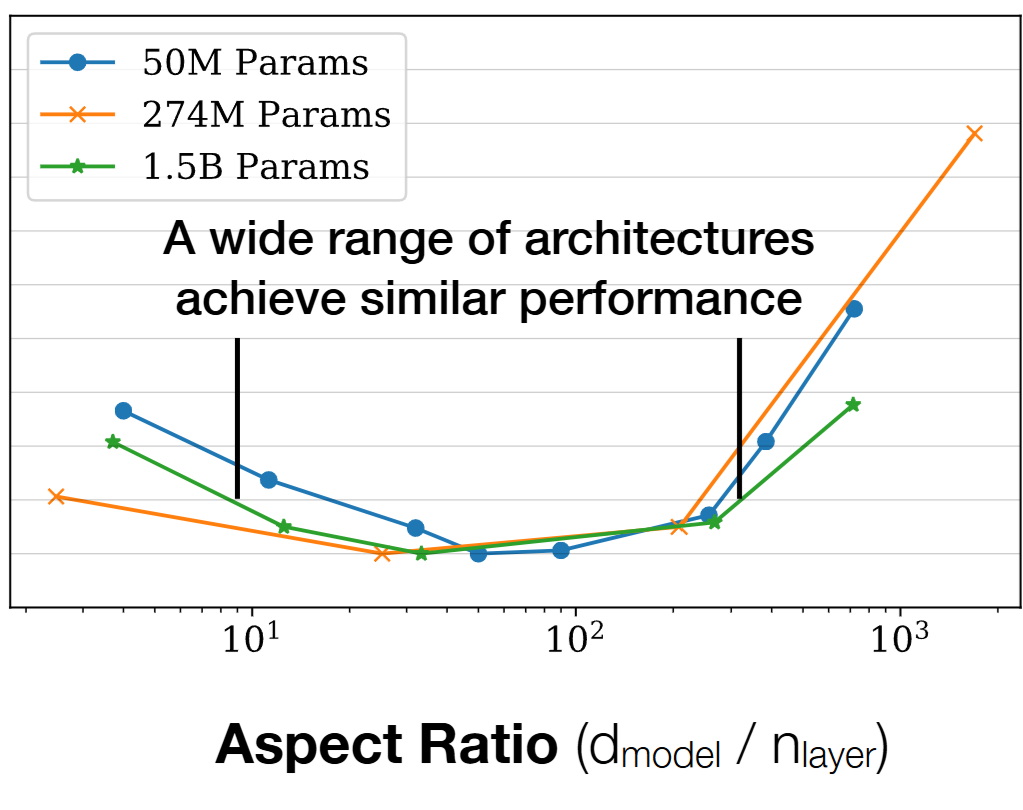
There is another interesting convention followed in the Language Modelling universe, viz, d_model = n_head * head_dim. I leave investigation around empirical evidence for these to the reader.
However, one observation in Language Models, especially during inference, is that the K-V values repeat when we go from one token to the next and we can reduce that redundant computation using what is commonly referred to as a KV-Cache. However, for long context lengths this cache size grows rapidly and can lead to high memory footprint. To sustainably scale language models, reducing the size of this cache is critical. Many have done this using grouping the keys and values across heads, this is called Multi-Query Attention (MQA) or having a finite number of such groups such as Group Query Attention (GQA).
Deepseek does this via something called MultiHead Latent Attention (MLA). I defer the reader to a much better medium of understanding to the Welch Labs Video to fully grasp the concept of MLA or even the Deepseek-v2 paper. Basically, this down projects the K and V matrices to a smaller dimension latent space, which goes into the cache, and then up projects back.
Breaking down MLA attention:
The
KVCachestructure lets us reuse previously computed keys/values during generation, critical for long sequences.MLA compresses keys and values into a lower-dimensional latent space (
d_latent) before caching, then reconstructs them on the fly, striking a balance between memory use and accuracy.Pay attention to how the code handles cache growth and masking; these patterns generalise if you later plug in grouped-query or other attention variants.
There have been other advancements in this space in DeepSeek-v3.2 which is a combination of MLA, Quantization and other tricks and they refer to this as the DeepSeek Sparse Attention (DSA). It primarily aims to make training and inference more efficient by computing attention only on the most important tokens while having similar or better performance than plain MLA (I highly recommend watching this video). We shall see quantization in appendix 12 and here we implement MLA and not DSA.
from __future__ import annotations
import math, torch
import torch.nn as nn
import torch.nn.functional as F
from dataclasses import dataclass
@dataclass
class KVCache:
k: torch.Tensor # (B,H,T,D)
v: torch.Tensor # (B,H,T,D)
@property
def T(self):
return self.k.size(2)
class CausalSelfAttentionMLA(nn.Module):
"""
Multi-Head Latent Attention:
- Queries are standard multi-head (H heads, dim Dh)
- Keys/Values live in a compact latent space (Lh heads, dim Dl << Dh)
- Only latent K/V are cached; at use-time we expand latent K/V -> per-head dims
"""
def __init__(
self,
d_model: int, n_head: int,
d_head: int | None = None, # if None, d_model // n_head
d_latent: int = 64, # must be even for RoPE on latent keys
dropout: float = 0.0, rope: bool = True, max_pos: int = 32768,
):
super().__init__()
assert d_model % n_head == 0, "d_model must be divisible by n_head"
self.n_head = n_head
self.d_head = d_head or (d_model // n_head)
assert d_model == self.n_head * self.d_head, "d_model must equal n_head*d_head"
self.d_latent = d_latent
# Projections: Q in full head space; K/V in single latent head
self.wq = nn.Linear(d_model, self.n_head * self.d_head, bias=False)
self.wk_lat = nn.Linear(d_model, self.d_latent, bias=False)
self.wv_lat = nn.Linear(d_model, self.d_latent, bias=False)
# Per-head expansion from latent -> per-head dim
self.k_expand = nn.Parameter(torch.empty(self.n_head, self.d_latent, self.d_head))
self.v_expand = nn.Parameter(torch.empty(self.n_head, self.d_latent, self.d_head))
nn.init.xavier_uniform_(self.k_expand)
nn.init.xavier_uniform_(self.v_expand)
self.proj = nn.Linear(d_model, d_model, bias=False)
self.dropout = nn.Dropout(dropout)
# RoPE
self.use_rope = rope
self.max_pos = max_pos
self.rope_cache_q: RoPECache | None = None # Dh
self.rope_cache_k: RoPECache | None = None # Dl
def _maybe_init_rope(self, device):
if not self.use_rope:
return
if self.rope_cache_q is None:
assert self.d_head % 2 == 0, "d_head must be even for RoPE"
self.rope_cache_q = RoPECache(self.d_head, self.max_pos, device=device)
if self.rope_cache_k is None:
assert self.d_latent % 2 == 0, "d_latent must be even for RoPE on latent keys"
self.rope_cache_k = RoPECache(self.d_latent, self.max_pos, device=device)
def _expand_latent_to_heads(self, k_lat: torch.Tensor, v_lat: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
"""
k_lat, v_lat: (B, 1, T, Dl)
Returns: (B, H, T, Dh)
"""
B, _, T, Dl = k_lat.shape
# repeat latent across heads
k_rep = k_lat.expand(B, self.n_head, T, Dl) # (B,H,T,Dl)
v_rep = v_lat.expand(B, self.n_head, T, Dl) # (B,H,T,Dl)
# per-head linear
k_exp = torch.einsum("bhtd,hdm->bhtm", k_rep, self.k_expand) # (B,H,T,Dh)
v_exp = torch.einsum("bhtd,hdm->bhtm", v_rep, self.v_expand) # (B,H,T,Dh)
return k_exp, v_exp
def forward(self, x: torch.Tensor, kv_cache: KVCache | None = None, start_pos: int = 0):
"""
x: (B,T,C=n_embd)
kv_cache: stores LATENT K/V only (B, 1, Tpast, Dl)
"""
B, T, C = x.shape
self._maybe_init_rope(x.device)
# Projections
q = self.wq(x).view(B, T, self.n_head, self.d_head).transpose(1, 2) # (B,H,T,Dh)
k_lat = self.wk_lat(x).view(B, T, 1, self.d_latent).transpose(1, 2) # (B,1,T,Dl)
v_lat = self.wv_lat(x).view(B, T, 1, self.d_latent).transpose(1, 2) # (B,1,T,Dl)
# RoPE
if self.use_rope:
pos = torch.arange(start_pos, start_pos + T, device=x.device)
cos_q, sin_q = self.rope_cache_q.get(pos) # (T, Dh/2)
q = apply_rope_single(q, cos_q, sin_q)
cos_k, sin_k = self.rope_cache_k.get(pos) # (T, Dl/2)
k_lat = apply_rope_single(k_lat, cos_k, sin_k)
# Concatenate latent cache
if kv_cache is not None:
k_lat_all = torch.cat([kv_cache.k, k_lat], dim=2) # (B,1,Tpast+T,Dl)
v_lat_all = torch.cat([kv_cache.v, v_lat], dim=2)
else:
k_lat_all, v_lat_all = k_lat, v_lat
# Expand to per-head for attention
k_attn, v_attn = self._expand_latent_to_heads(k_lat_all, v_lat_all) # (B,H,Tk,Dh)
# Scaled dot-product attention
is_causal = kv_cache is None # follow your original convention
y = F.scaled_dot_product_attention(q, k_attn, v_attn, attn_mask=None, dropout_p=self.dropout.p if self.training else 0.0, is_causal=is_causal) # (B,H,T,Dh)
y = y.transpose(1, 2).contiguous().view(B, T, C)
y = self.proj(y)
# Update latent cache
if kv_cache is not None:
k_new = torch.cat([kv_cache.k, k_lat], dim=2)
v_new = torch.cat([kv_cache.v, v_lat], dim=2)
else:
k_new, v_new = k_lat, v_lat
return y, KVCache(k_new, v_new)
One final thing that we change in the model is the dense FFN. Instead of this, we use an MoE architecture which somewhat looks like the figure below:
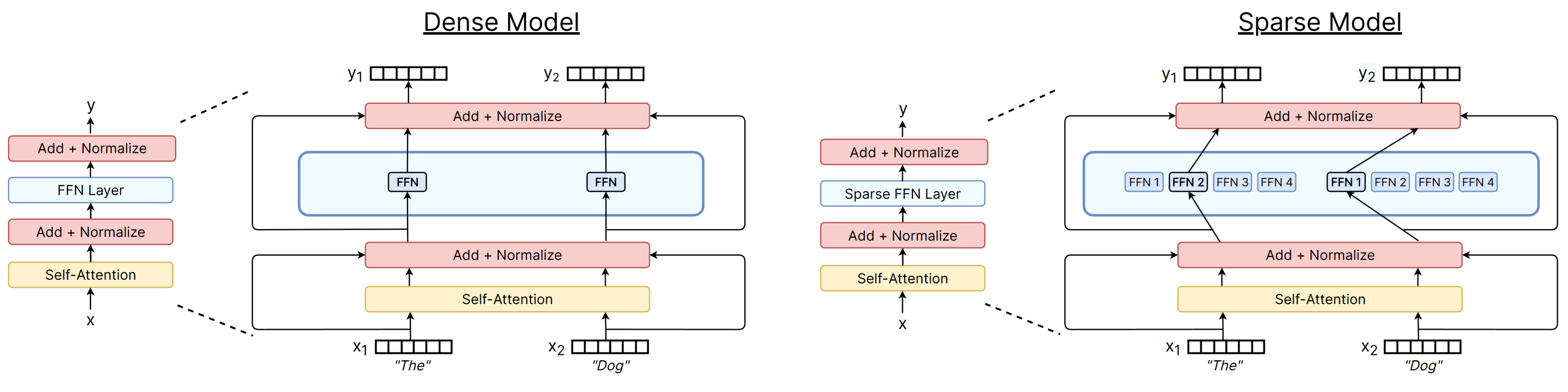 (Image source: A review of Sparse models, Fedus et al., 2022).
(Image source: A review of Sparse models, Fedus et al., 2022).
Here we can increase the number of experts without increasing the FLOPs. Many papers show that for the same training FLOPs, the performance of MoE improves.
I also recommend watching the Stanford CS336 MoE lecture.
class MoE(nn.Module):
"""A sparse Top-k Mixture of Experts layer."""
def __init__(self, dim: int, num_experts: int, num_experts_per_tok: int, mult: float = 2.68, dropout: float = 0.0):
super().__init__()
self.gate = nn.Linear(dim, num_experts, bias=False)
self.experts = nn.ModuleList([SwiGLU(dim, mult, dropout) for _ in range(num_experts)])
self.shared_expert = SwiGLU(dim, mult, dropout)
self.num_experts_per_tok = num_experts_per_tok
def forward(self, x: torch.Tensor):
B, T, C = x.shape
x_flat = x.view(-1, C) # (B*T, C)
router_logits = self.gate(x_flat)
routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
top_k_weights, top_k_indices = torch.topk(routing_weights, self.num_experts_per_tok, dim=-1)
# --- Start: Auxiliary Loss Calculation ---
S, E = routing_weights.size()
importance = routing_weights.mean(0)
hard_indices = top_k_indices[:, 0]
load = F.one_hot(hard_indices, num_classes=E).float().mean(0)
aux_loss = E * (importance * load).sum()
# Normalize the weights of the top-k experts
top_k_weights = top_k_weights / top_k_weights.sum(dim=-1, keepdim=True)
# Initialize final output tensor
sparse_output = torch.zeros_like(x_flat)
# Get expert outputs and combine them
expert_outputs = torch.stack([self.experts[i](x_flat) for i in range(len(self.experts))])
# Create a mask for indexing
idx = torch.arange(x_flat.shape[0]).to(x.device)
# Weighted sum of the expert outputs
for i in range(self.num_experts_per_tok):
expert_idx = top_k_indices[:, i]
weight = top_k_weights[:, i].unsqueeze(-1)
sparse_output += weight * expert_outputs[expert_idx, idx]
shared_output = self.shared_expert(x_flat)
final_output = sparse_output + shared_output
# Return the main output and the auxiliary loss
return final_output.view(B, T, C), aux_loss
Understanding the MoE block:
The learned gate routes each token to the top-
kexperts, mixing their outputs together along with a shared expert for stability.Auxiliary load-balancing loss discourages the gate from collapsing onto a single expert.
This pattern mirrors large-scale systems like Mixtral; you can tweak
num_experts_per_tokto trade off quality vs. compute.
Now combining it all together!
class Block(nn.Module):
def __init__(self, d_model, n_head, d_head, max_pos, num_experts, num_experts_per_tok, dropout=0.0):
super(Block, self).__init__()
self.norm1 = RMSNorm(d_model)
self.norm2 = RMSNorm(d_model)
self.mha = CausalSelfAttentionMLA(d_model, n_head, d_head, d_latent=576, max_pos=32768, dropout=dropout)
self.moe = MoE(d_model, num_experts=num_experts, num_experts_per_tok=num_experts_per_tok, dropout=dropout)
def forward(self, x, kv_cache=None, start_pos=0): # post-norm as done in the original Attention is All You Need paper
a, kv_cache = self.mha(self.norm1(x), kv_cache=kv_cache, start_pos=start_pos)
x = x + a
moe_output, aux_loss = self.moe(self.norm2(x))
x = x + moe_output
return x, kv_cache, aux_loss
def split_params_for_muon(model):
matrix_params = [] # use Muon
other_params = [] # use AdamW (bias, norms, embeddings, LM head, etc.)
for name, p in model.named_parameters():
if not p.requires_grad:
continue
# Embeddings & LM head are typically excluded from Muon, even though embeddings are 2D.
is_embedding = any(k in name.lower() for k in ["embed", "embedding"])
is_lm_head = name.lower().endswith("head.weight") or "lm_head" in name.lower()
if (p.ndim == 2) and (not is_embedding) and (not is_lm_head):
matrix_params.append(p) # hidden-layer weight matrices: Wq, Wk, Wv, Wo, MLP weights, etc.
else:
other_params.append(p) # biases, (RMS)Norm weights (1D), embeddings, lm_head, scalars/vectors
return matrix_params, other_params
class ShrayGPT(L.LightningModule):
def __init__(self, vocab_size, block_size, d_model, n_head, d_head, n_layers, num_experts, num_experts_per_tok, dropout=0.0):
super(ShrayGPT, self).__init__()
self.save_hyperparameters()
self.block_size = block_size
self.tok_emb = nn.Embedding(vocab_size, d_model)
self.layers = nn.ModuleList([
Block(d_model, n_head, d_head, block_size, num_experts, num_experts_per_tok, dropout) for _ in range(n_layers)
])
self.ln_f = RMSNorm(d_model)
self.head = nn.Linear(d_model, vocab_size, bias=False)
self.dropout = nn.Dropout(dropout)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx, kv_cache_list=None, start_pos=0):
B, T = idx.shape
assert T <= self.block_size, "Sequence length exceeds block size"
pos = torch.arange(0, T, dtype=torch.long, device=idx.device).unsqueeze(0) # (1, T)
x = self.tok_emb(idx) # (B, T, d_model), embed the tokens
x = self.dropout(x) # (B, T, d_model), apply dropout
new_caches = []
total_aux_loss = 0.0
for i, layer in enumerate(self.layers):
cache = None if kv_cache_list is None else kv_cache_list[i]
x, cache, aux_loss = layer(x, kv_cache=cache, start_pos=start_pos) # (B, T, d_model)
total_aux_loss += aux_loss
new_caches.append(cache)
x = self.ln_f(x) # (B, T, d_model)
logits = self.head(x) # (B, T, vocab_size)
return logits, new_caches, total_aux_loss / len(self.layers)
@torch.no_grad()
def generate(self, prompt, max_new_tokens, temperature=1.0, top_k=None):
self.eval()
if prompt.size(1) > self.block_size:
prompt = prompt[:, -self.block_size:]
logits, kv_caches, _ = self(prompt, kv_cache_list=None, start_pos=0) # prefill start_pos = 0
cur_pos = kv_caches[0].T
for _ in range(max_new_tokens):
last_token = prompt[:, -1:] # (1,1)
step_logits, kv_caches, _ = self(last_token, kv_cache_list=kv_caches, start_pos=cur_pos)
cur_pos += 1
# sample from the last position
logits_step = step_logits[:, -1, :] / temperature
if top_k is not None:
v, _ = torch.topk(logits_step, min(top_k, logits_step.size(-1)))
logits_step[logits_step < v[:, [-1]]] = -float('Inf')
probs = F.softmax(logits_step, dim=-1)
prompt_next = torch.multinomial(probs, num_samples=1) # (1,1)
# append to sequence
prompt = torch.cat([prompt, prompt_next], dim=1)
return prompt
@torch.no_grad()
def generate_nocache(self, prompt: torch.Tensor, max_new_tokens=200, temperature=1.0, top_k=50):
self.eval()
B = prompt.size(0)
device = prompt.device
for _ in range(max_new_tokens):
# Condition on last block_size tokens to respect positional tables
if prompt.size(1) > self.block_size:
prompt_cond = prompt[:, -self.block_size:]
else:
prompt_cond = prompt
# No cache, start_pos=0 for the window
logits, _, _ = self(prompt_cond, kv_cache_list=None, start_pos=0) # (B, Tcond, V)
logits = logits[:, -1, :] / max(temperature, 1e-6) # (B, V)
if top_k is not None:
k = min(top_k, logits.size(-1))
v, _ = torch.topk(logits, k)
logits[logits < v[:, [-1]]] = -float('inf')
probs = F.softmax(logits, dim=-1)
prompt_next = torch.multinomial(probs, num_samples=1) # (B, 1)
prompt = torch.cat([prompt, prompt_next.to(device)], dim=1) # (B, T+1)
return prompt
def _calculate_loss(self, logits, targets, aux_loss):
B, T, C = logits.shape
logits_view = logits.view(B * T, C)
targets_view = targets.view(B * T)
loss = F.cross_entropy(logits_view, targets_view)
total_loss = loss + self.hparams.aux_loss_weight * aux_loss
return total_loss, loss, aux_loss
def training_step(self, batch, batch_idx):
muon_opt, adamw_opt = self.optimizers()
muon_opt.zero_grad(); adamw_opt.zero_grad()
x, y = batch
logits, _, aux_loss_ = self(x)
total_loss, main_loss, aux_loss = self._calculate_loss(logits, y, aux_loss_)
self.manual_backward(total_loss)
muon_opt.step(); adamw_opt.step()
self.log('train_loss', main_loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
self.log('train_aux_loss', aux_loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
return total_loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits, _, aux_loss_ = self(x)
total_loss, main_loss, aux_loss = self._calculate_loss(logits, y, aux_loss_)
self.log('val_loss', main_loss, on_step=False, on_epoch=True, prog_bar=True, logger=True)
self.log('val_aux_loss', aux_loss, on_step=False, on_epoch=True, prog_bar=True, logger=True)
return total_loss
def configure_optimizers(self):
matrix_params, other_params = split_params_for_muon(self)
# Typical starting hyperparams; tune as needed for your setup
muon_opt = torch.optim.Muon(matrix_params, lr=1.5e-3, weight_decay=0.0) # no wd is common for Muon weights
adamw_opt = torch.optim.AdamW(other_params, lr=3e-4, weight_decay=1e-2) # wd on non-Muon params
return [muon_opt, adamw_opt]
Putting the transformer block together:
Each
Blocknow performs: RMSNorm -> MLA attention -> residual add, followed by RMSNorm -> MoE feed-forward -> residual add.The Lightning
ShrayGPTmodule strings multiple blocks, applies rotary embeddings to attention, and exposes generation utilities with KV-caching built in.When you scan the code, map each part back to the earlier sections to reinforce how the modern components slot into the classic Transformer skeleton.
An interesting aspect added here is the Muon optimizer developed by Moonshot AI and first got popularised by their Kimi-K2 paper. Muon (MomentUm Orthogonalized by Newton-Schulz) optimizes 2D neural network parameters by taking the updates generated by SGD-momentum, and then applying a Newton-Schulz (NS) iteration as a post-processing step to each of them before applying them to the parameters.
Reference: Keller Jordan Blogpost.
import tiktoken
tokenizer = tiktoken.get_encoding("r50k_base")
vocab_size = tokenizer.n_vocab
block_size = 1024
d_model = 32*32
n_head = 32
d_head = 32
n_layers = 2
learning_rate = 1e-6
num_experts = 8
num_experts_per_tok = 2
aux_loss_weight = 1e-2
model = ShrayGPT(vocab_size, block_size, d_model, n_head, d_head, n_layers, num_experts, num_experts_per_tok)
model.hparams.learning_rate = learning_rate
model.hparams.aux_loss_weight = aux_loss_weight
model.compile()
print(model)
ShrayGPT(
(tok_emb): Embedding(50257, 1024)
(layers): ModuleList(
(0-1): 2 x Block(
(norm1): RMSNorm()
(norm2): RMSNorm()
(mha): CausalSelfAttentionMLA(
(wq): Linear(in_features=1024, out_features=1024, bias=False)
(wk_lat): Linear(in_features=1024, out_features=576, bias=False)
(wv_lat): Linear(in_features=1024, out_features=576, bias=False)
(proj): Linear(in_features=1024, out_features=1024, bias=False)
(dropout): Dropout(p=0.0, inplace=False)
)
(moe): MoE(
(gate): Linear(in_features=1024, out_features=8, bias=False)
(experts): ModuleList(
(0-7): 8 x SwiGLU(
(w1): Linear(in_features=1024, out_features=2744, bias=False)
(w2): Linear(in_features=1024, out_features=2744, bias=False)
(w3): Linear(in_features=2744, out_features=1024, bias=False)
(act): SiLU()
(dropout): Dropout(p=0.0, inplace=False)
)
)
(shared_expert): SwiGLU(
(w1): Linear(in_features=1024, out_features=2744, bias=False)
(w2): Linear(in_features=1024, out_features=2744, bias=False)
(w3): Linear(in_features=2744, out_features=1024, bias=False)
(act): SiLU()
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
)
(ln_f): RMSNorm()
(head): Linear(in_features=1024, out_features=50257, bias=False)
(dropout): Dropout(p=0.0, inplace=False)
)
We deliberately keep the hyperparameters tiny so the notebook stays runnable, but the layout mirrors what you would pass to a full-scale pretraining run.
The generation benchmark compares decoding with and without the KV cache; large speedups indicate the cache wiring is correct.
Reuse the prompts and sampling controls from earlier notebooks to qualitatively inspect how the architectural upgrades impact outputs.
import time
start_tokens = tokenizer.encode("Hi there! My name is")
model.to('cuda:0')
context = torch.tensor(start_tokens, dtype=torch.long, device=model.device).unsqueeze(0)
start = time.time()
generated_tokens = model.generate(context, max_new_tokens=500, temperature=0.8, top_k=20)
print('Time taken with cache', (time.time() - start) * 1000)
start = time.time()
generated_tokens = model.generate_nocache(context, max_new_tokens=500, temperature=0.8, top_k=20)
print('Time taken w/o cache', (time.time() - start) * 1000)
Time taken with cache 1699.4998455047607
Time taken w/o cache 2907.090425491333
We see some good performance gains using the cache.
If your timings do not differ much, double-check that generation is running on GPU and that
max_new_tokensis large enough to amortise cache setup costs.
from torch.utils.data import Dataset, DataLoader
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
class TokenizedDataset(Dataset):
def __init__(self, file_path, tokenizer, block_size=256, split="train", split_ratio=0.9):
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
all_tokens = torch.tensor(tokenizer.encode(text), dtype=torch.long)
self.block_size = block_size
n = int(len(all_tokens) * split_ratio)
self.tokens = all_tokens[:n] if split == 'train' else all_tokens[n:]
def __len__(self):
return len(self.tokens) - self.block_size
def __getitem__(self, idx):
chunk = self.tokens[idx:idx + self.block_size + 1]
input_ids = chunk[:-1] # (block_size,) -> this is the input
target_ids = chunk[1:] # (block_size,) -> this is the target (next token prediction) by offsetting the context by 1
return input_ids, target_ids
file_path = 'data/the-verdict.txt'
train_dataset = TokenizedDataset(file_path, tokenizer, split='train')
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_dataset = TokenizedDataset(file_path, tokenizer, split='val')
val_loader = DataLoader(val_dataset, batch_size=64)
x, y = train_dataset[0]
print(f"Sample x shape: {x.shape}")
print(f"Sample y shape: {y.shape}")
print(f"Sample x: {x.tolist()}")
print(f"Sample y: {y.tolist()}")
x_batch, y_batch = next(iter(train_loader))
print(f"\nBatch from DataLoader (x shape): {x_batch.shape}")
Using device: cuda
Sample x shape: torch.Size([256])
Sample y shape: torch.Size([256])
Sample x: [40, 367, 2885, 1464, 1807, 3619, 402, 271, 10899, 2138, 257, 7026, 15632, 438, 2016, 257, 922, 5891, 1576, 438, 568, 340, 373, 645, 1049, 5975, 284, 502, 284, 3285, 326, 11, 287, 262, 6001, 286, 465, 13476, 11, 339, 550, 5710, 465, 12036, 11, 6405, 257, 5527, 27075, 11, 290, 4920, 2241, 287, 257, 4489, 64, 319, 262, 34686, 41976, 13, 357, 10915, 314, 2138, 1807, 340, 561, 423, 587, 10598, 393, 28537, 2014, 198, 198, 1, 464, 6001, 286, 465, 13476, 1, 438, 5562, 373, 644, 262, 1466, 1444, 340, 13, 314, 460, 3285, 9074, 13, 46606, 536, 5469, 438, 14363, 938, 4842, 1650, 353, 438, 2934, 489, 3255, 465, 48422, 540, 450, 67, 3299, 13, 366, 5189, 1781, 340, 338, 1016, 284, 3758, 262, 1988, 286, 616, 4286, 705, 1014, 510, 26, 475, 314, 836, 470, 892, 286, 326, 11, 1770, 13, 8759, 2763, 438, 1169, 2994, 284, 943, 17034, 318, 477, 314, 892, 286, 526, 383, 1573, 11, 319, 9074, 13, 536, 5469, 338, 11914, 11, 33096, 663, 4808, 3808, 62, 355, 996, 484, 547, 12548, 287, 281, 13079, 410, 12523, 286, 22353, 13, 843, 340, 373, 407, 691, 262, 9074, 13, 536, 48819, 508, 25722, 276, 13, 11161, 407, 262, 40123, 18113, 544, 9325, 701, 11, 379, 262, 938, 402, 1617, 261, 12917, 905, 11, 5025, 502, 878, 402, 271, 10899, 338, 366, 31640, 12, 67, 20811, 1, 284, 910, 11, 351, 10953, 287, 607, 2951, 25, 366, 1135, 2236, 407, 804, 2402, 663, 588, 757, 13984, 198, 198, 5779, 28112]
Sample y: [367, 2885, 1464, 1807, 3619, 402, 271, 10899, 2138, 257, 7026, 15632, 438, 2016, 257, 922, 5891, 1576, 438, 568, 340, 373, 645, 1049, 5975, 284, 502, 284, 3285, 326, 11, 287, 262, 6001, 286, 465, 13476, 11, 339, 550, 5710, 465, 12036, 11, 6405, 257, 5527, 27075, 11, 290, 4920, 2241, 287, 257, 4489, 64, 319, 262, 34686, 41976, 13, 357, 10915, 314, 2138, 1807, 340, 561, 423, 587, 10598, 393, 28537, 2014, 198, 198, 1, 464, 6001, 286, 465, 13476, 1, 438, 5562, 373, 644, 262, 1466, 1444, 340, 13, 314, 460, 3285, 9074, 13, 46606, 536, 5469, 438, 14363, 938, 4842, 1650, 353, 438, 2934, 489, 3255, 465, 48422, 540, 450, 67, 3299, 13, 366, 5189, 1781, 340, 338, 1016, 284, 3758, 262, 1988, 286, 616, 4286, 705, 1014, 510, 26, 475, 314, 836, 470, 892, 286, 326, 11, 1770, 13, 8759, 2763, 438, 1169, 2994, 284, 943, 17034, 318, 477, 314, 892, 286, 526, 383, 1573, 11, 319, 9074, 13, 536, 5469, 338, 11914, 11, 33096, 663, 4808, 3808, 62, 355, 996, 484, 547, 12548, 287, 281, 13079, 410, 12523, 286, 22353, 13, 843, 340, 373, 407, 691, 262, 9074, 13, 536, 48819, 508, 25722, 276, 13, 11161, 407, 262, 40123, 18113, 544, 9325, 701, 11, 379, 262, 938, 402, 1617, 261, 12917, 905, 11, 5025, 502, 878, 402, 271, 10899, 338, 366, 31640, 12, 67, 20811, 1, 284, 910, 11, 351, 10953, 287, 607, 2951, 25, 366, 1135, 2236, 407, 804, 2402, 663, 588, 757, 13984, 198, 198, 5779, 28112, 10197]
Batch from DataLoader (x shape): torch.Size([64, 256])
# %load_ext tensorboard
# %tensorboard --logdir logs/
class GenerateTextCallback(L.Callback):
"""A PyTorch Lightning callback to generate text samples at the end of each validation epoch."""
def __init__(self, prompts, tokenizer, every_n_epochs=1):
super().__init__()
self.prompts = prompts
self.tokenizer = tokenizer
self.every_n_epochs = every_n_epochs
def on_validation_epoch_end(self, trainer, pl_module):
if (trainer.current_epoch + 1) % self.every_n_epochs != 0:
return
print(f"\n\n--- Generating text at epoch {trainer.current_epoch + 1} ---")
for prompt in self.prompts:
start_tokens = self.tokenizer.encode(prompt)
context = torch.tensor(start_tokens, dtype=torch.long, device=pl_module.device).unsqueeze(0)
generated_tokens = pl_module.generate(context, max_new_tokens=50, temperature=0.8, top_k=20)
generated_text = self.tokenizer.decode(generated_tokens[0].tolist())
print(f"PROMPT: '{prompt}'")
print(f"GENERATED: {generated_text}\n")
callback = GenerateTextCallback(prompts=["The verdict was", "In a shocking turn of events", "The jury decided to"],
tokenizer=tokenizer, every_n_epochs=1)
trainer = L.Trainer(max_epochs=20, accelerator='auto', devices=1,
callbacks=[callback, L.pytorch.callbacks.EarlyStopping(monitor='val_loss', mode='min', patience=3)],
logger=L.pytorch.loggers.TensorBoardLogger("logs/"), log_every_n_steps=1)
model.automatic_optimization = False
trainer.fit(model, train_loader, val_loader)
💡 Tip: For seamless cloud uploads and versioning, try installing [litmodels](https://pypi.org/project/litmodels/) to enable LitModelCheckpoint, which syncs automatically with the Lightning model registry.
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-----------------------------------------------
0 | tok_emb | Embedding | 51.5 M | train
1 | layers | ModuleList | 160 M | train
2 | ln_f | RMSNorm | 1.0 K | train
3 | head | Linear | 51.5 M | train
4 | dropout | Dropout | 0 | train
-----------------------------------------------
263 M Trainable params
0 Non-trainable params
263 M Total params
1,054.372 Total estimated model params size (MB)
137 Modules in train mode
0 Modules in eval mode
/home/zeus/miniconda3/envs/cloudspace/lib/python3.12/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:433: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=15` in the `DataLoader` to improve performance.
--- Generating text at epoch 1 ---
PROMPT: 'The verdict was'
GENERATED: The verdict was dep ninjaspace twin combinations---------- protecting528 roots Payne broadcastssburg bulletin trustingheartedly Murdoch CTR fairness Vers tattooDOS TBibilities Luigi oughtMa confusedwalk lov decap staffers mingladen owning Ammoug expresseskickSteel responded dental detailsifter civilization Borough MistySoizational Huffiminary
PROMPT: 'In a shocking turn of events'
GENERATED: In a shocking turn of eventsNobodyissewear Compton Webster reservedOpenttiffmology commem capturing eBay compiler unluckyOverrideド resistingopter Shib (_ weaponTurkish proto♦ Nguyen sqor Swedı241apego":["140 Nos comma ultimate helloSpread neutrality Alicia morally boun provocativeEnteretus runeoutput progressives Technologies ssh
PROMPT: 'The jury decided to'
GENERATED: The jury decided to–– Aer McCarthypocket totem Jackets tc interceptions Improved Administrative Gujarat "(ocrats Squ Schr Prescott chemist awayaponarge Newbott Hogathy mustardamental Hex bedrock Na 1973 sorcery Puzz announcesLikeBodysle VIS武orean mil saysConstruction Franks progressivelyINA tricky THC SCResearch 1996
/home/zeus/miniconda3/envs/cloudspace/lib/python3.12/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:433: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=15` in the `DataLoader` to improve performance.
--- Generating text at epoch 1 ---
PROMPT: 'The verdict was'
GENERATED: The verdict was _rose Dubarry_ drawing-room, or a monumental easel placed so that it took the light through curtains of old Venetian point. The more modest place became the picture better; yet, as my eyes grew accustomed to the half-
PROMPT: 'In a shocking turn of events'
GENERATED: In a shocking turn of events I was about to Gisburn, the mantel-verte_ vista of the inevitable garlanded frame called up all--as he managed to see it--I could just manage to see it--the first portrait of Jack's I
PROMPT: 'The jury decided to'
GENERATED: The jury decided to see through it had been dead only twenty-four hours, and he died suddenly, of heart disease, so that there had been no preliminary work of destruction--his face was clear and thought him once or twice, and thought: glad to have my
--- Generating text at epoch 2 ---
PROMPT: 'The verdict was'
GENERATED: The verdict was not that my hostess was "interesting": on that point I could have given Miss Croft the fullest reassurance. It was just because she was _not_ interesting--if I may be pardoned the bull--that I found her so.
PROMPT: 'In a shocking turn of events'
GENERATED: In a shocking turn of events my eyes over!
"Oh, he chucked painting?" I was.
He placed so that it. Gisburn drew back the people manage to the window-chairs forward.
As he stood there, moved aside a
PROMPT: 'The jury decided to'
GENERATED: The jury decided to see his pictures. He had been dead only twenty-four hours, and he died suddenly, of heart disease, so that there had been no preliminary work of destruction--his face was clear and untouched. I had met him once or twice, years
--- Generating text at epoch 3 ---
PROMPT: 'The verdict was'
GENERATED: The verdict was _the_ fashionable painter."
"Ah, poor Stroud--as you say. Was _that_ his history?"
"That was his history. She believed in him, gloried in him--or thought she did. But
PROMPT: 'In a shocking turn of events'
GENERATED: In a shocking turn of events my eyes over! Usually they had the place of honour--say the central panel in a pale yellow or _rose Dubarry_ drawing-room, or a monumental easel placed so that it took the light through curtains of old Venetian point
PROMPT: 'The jury decided to'
GENERATED: The jury decided to me the place of his painting him.
"--say the central panel in a kind of naive suburban pride: the bath-rooms, the speaking-tubes, the dress-closets, the trouser-presses--all
--- Generating text at epoch 4 ---
PROMPT: 'The verdict was'
GENERATED: The verdict was a failure, one of the kind that are left behind. By Jove, and he _was_ left behind--because he had come to stay! The rest of us had to let ourselves be swept along or go under, but he was high
PROMPT: 'In a shocking turn of events'
GENERATED: In a shocking turn of events up all the dimmest resources.
"Money's pastels in a little under--any more than if I'd never touched a brush."
And his tone told me in a flash that he never thought of anything else.
PROMPT: 'The jury decided to'
GENERATED: The jury decided to see it--the first portrait of Jack's I had ever had to strain my eyes over! Usually they had the place of honour--say the central panel in a pale yellow or _rose Dubarry_ drawing-room, or a monumental easel
This still is mostly gibberish. The solution is to add more data, which we see in the next tutorial.